こんにちは。NETCON委員のizuminです。
JANOG53では問題を作成したので解説します!
ここでは私が作成した4問のうちLevel 2-3を解説します。
その他の3問はこちら。



問題
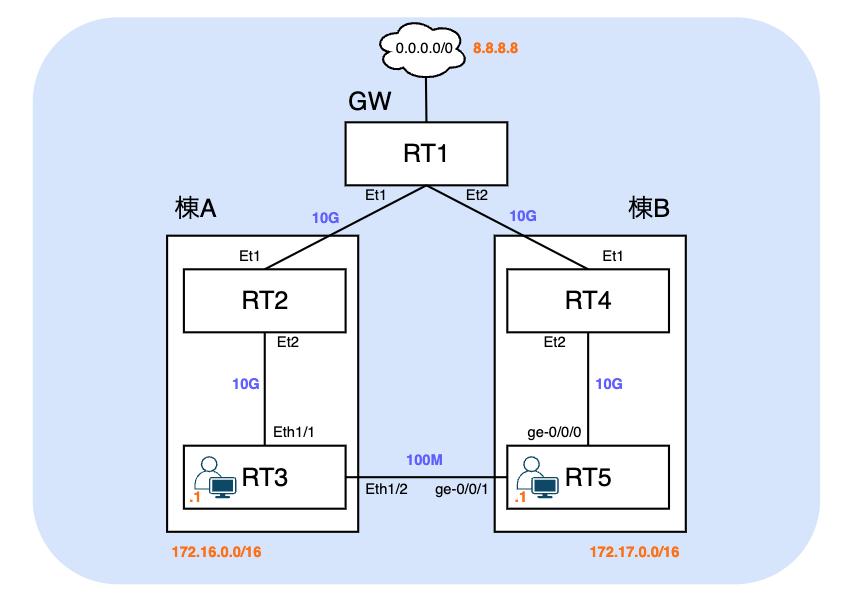
あなたはとある会社のネットワークを運用しています。
棟AのRT3, 棟BのRT5にはユーザーが収容されています。
ある日あなたは下記の点を考え、RT3-RT5の直接接続を検討しました。
・RT2,RT4で障害が発生した際の最小限のインターネットBackup用
・棟間の直接通信
そして、100Mの棟間配線の用意ができたため、本日RT3とRT5の開通作業を実施したところ、
棟Aのユーザーからパブリッククラウドストレージへのアップロードにやたら時間がかかると報告がありました。
棟Bのユーザーに確認すると特にそのような問題は起きていないようでした。
すぐに解決できないため、開通した専用線は一度shutして、深夜に是正することにしました。
そして時刻は深夜25時になりました。
あなた >「おかしいなぁ。なんで棟Aだけで問題が起きているんだろう。。あっ… そうか!!」
あなたは何かに気づいたようです。早速是正作業に取り掛かりましょう。
ヒント
・Internetを模擬して8.8.8.8がRT1のLoopbackに設定されています。
・RT3, RT5にもユーザーを模擬したアドレスがLoopbackに設定されています。pingを打つときはsourceで指定してください。
ping 8.8.8.8 source 172.16.0.1
ping 8.8.8.8 source 172.17.0.1

解説-設定例
## RT3
+ route-map AD_BGP150 permit 10
+ match ip address prefix-list DEFAULT_ROUTE
+ set distance 200 200 200
router bgp 65001
address-family ipv4 unicast
network 172.16.0.0/16
redistribute ospf 1 route-map OSPF_to_BGP
+ table-map AD_BGP150解説-概要
ベンダーによってプロトコルのAD値が違うことにより意図しない細い経路を通ってしまうことが原因となる問題でした。
下の図のようにCiscoはeBGP優先、JunosはOSPF優先のため、Ciscoは拠点Bがベストパスになってしまい100Mの細い線を通ることになります。
帰りは直接拠点Aに帰ってきますが、上りトラフィックが拠点間で詰まったことで影響が出たと考えられる問題でした。
RT3にてDF経路を動的にRT2に向けることができれば問題は解消されます。

解説-詳細
概要にあったようにベンダーのAD値の実装が異なることにより、拠点A/拠点Bで違う経路を取ってしまう問題でした。
Juniperしか触ったことない人がOSPFが優先だと思い込んで設定したら今回のような障害を引き起こしてしまうかもしれません。
解決法はさまざまだと思いますが、ここではRT3のDefault RouteのDistanceをOSPFより下げることで解決する手法を取っています。
AD値を変更するなんてナンセンスと思うかもですが、NETCONの問題として出しているので綺麗な設計ではないことはご了承ください。。
専用線が開通する前は各拠点からシンプルにOSPFでGWに向いていましたが、開通してBGPを上げたことによりRT3のRIBが下のようになります。
この問題はこの状態でスタートします。見ての通り、RT3/RT5でDistanceの順序が違います。
## RT3
RT3(config-router-af)# show ip route 0.0.0.0/0
0.0.0.0/0, ubest/mbest: 1/0
*via 192.168.5.2, [20/0], 00:00:09, bgp-65001, external, tag 65002
via 192.168.3.1, Eth1/1, [110/11], 01:10:51, ospf-1, type-1
## RT5
admin@RT5> show route 0.0.0.0
0.0.0.0/0 *[OSPF/150] 01:19:12, metric 0, tag 0
> to 192.168.4.1 via ge-0/0/0.0
[BGP/170] 00:34:41, localpref 100
AS path: 65001 I, validation-state: unverified
> to 192.168.5.1 via ge-0/0/1.0Junos側と揃えたいのでCisco側のDistanceをTable-mapを利用して変更します。
すると下のようにOSPFが優先経路に変わりました。
RT3# show ip route 0.0.0.0/0
0.0.0.0/0, ubest/mbest: 1/0
*via 192.168.3.1, Eth1/1, [110/11], 01:09:34, ospf-1, type-1
via 192.168.5.2, [200/0], 00:24:30, bgp-65001, external, tag 65002他の達成条件の内容も見てみます。
「RT2,RT4のUplinkで障害が起きた際はBackup回線を利用してインターネットに疎通できるようにすること。」
RT1-RT2の部分がDownした場合、GWからOSPF経由で広報されたDFは消失します。
そのため、別拠点がベストパスになります。
RT3# show ip route 0.0.0.0/0
0.0.0.0/0, ubest/mbest: 1/0
*via 192.168.5.2, [20/0], 00:12:51, bgp-65001, external, tag 65002RT1側は元々各拠点の経路と他の拠点の経路をPrependした状態で広報されています。
RT1-RT2がDownした場合はRT1-RT4の経路がActiveになります。
## 正常時
RT1(config-if-Et1)#show ip bgp
Network Next Hop Metric AIGP LocPref Weight Path
* > 172.16.0.0/16 192.168.1.2 0 - 100 0 65001 i
* 172.16.0.0/16 192.168.2.2 0 - 100 0 65002 65002 i
* > 172.17.0.0/16 192.168.2.2 0 - 100 0 65002 i
* 172.17.0.0/16 192.168.1.2 0 - 100 0 65001 65001 i
## RT1-RT2がDown時
RT1(config-if-Et1)#show ip bgp
Network Next Hop Metric AIGP LocPref Weight Path
* > 172.16.0.0/16 192.168.2.2 0 - 100 0 65002 65002 i
* > 172.17.0.0/16 192.168.2.2 0 - 100 0 65002 iもう一つの条件である、
「各拠点のユーザセグメント間の通信はGWを経由しないこと。」
についてはGWはから受信することはないので、BGPさえ上がっていればロンゲストマッチでGWに引っ張られることはないため問題ありません。
さらに面白い話。
この問題を成り立たせるために、RT3ではBGP RIBにOSPFから受信している0.0.0.0/0をインジェクトしないようにしている。
afi ipv4 unicast配下で”default-infomation orignate”→RIBにデフォルトがいる場合はBGP RIBにインジェクトされる。
neighbor配下で”default-originate”→RIBにデフォルトが存在しない状態でもデフォルトを広報する。その際にBGP RIBに0.0.0.0/0が生成されることはない。
理由としてはインジェクトしてしまうと下記のような矛盾が生じる。
- OSPFでデフォルトルートを受信する。
- default-infomation originateでBGP RIBに0.0.0.0/0を自己生成する。
- RT5からBGPで0.0.0.0/0を受信する。
- 自己生成 > eBGPにより受信した経路は有効にならない。
- AD値はeBGP > OSPFのはずなのに OSPFの経路が有効のままになる。
default-originateで0.0.0.0をBGP RIBに生成しないことで下のようになる。
- OSPFでデフォルトルートを受信する。
- RT5からBGPで0.0.0.0/0を受信する。
- eBGPにより受信した経路がBGP RIBに乗る。
- AD値勝負に持ち込まれ、eBGP > OSPFでBGP経路が有効になる。
default-infomation originateを採用した場合は、学習のタイミングによってネクストホップが変わる変なネットワークができます。
今回は問題なのでContainerlabの起動順で経路が変わってしまっては問題として微妙だったので上記対応をしています。